
June 2, 2026

In 1951, the United States Air Force had a question that could not be answered by experiment: how many atomic bombs would be required to significantly disrupt U.S. industrial capacity under nuclear attack?
There were no historical precedents to draw on, no experiments to run, no datasets to analyse. All the Air Force had were experts, strategists, physicists, military planners and those experts disagreed with each other. Worse, when they were put in a room together, the usual dynamics took over: the most senior voice dominated, the most confident speaker anchored the discussion, and the quieter analysts who might have been closer to the truth stayed silent.
RAND Corporation researchers in Santa Monica, including Olaf Helmer, a mathematician and game theorist, and Norman Dalkey, a social psychologist, were tasked with solving this problem. Not the bombing question itself, but the meta-problem: how do you extract the most accurate collective judgement from a group of experts when hierarchy, personality, and groupthink distort the conversation?
Their solution was a structured process of anonymous questionnaires, iterative rounds, and controlled feedback. Experts would submit their estimates independently, without knowing who said what. After each round, they would see a statistical summary of the group’s responses and the reasoning behind outlier positions, then revise their own estimates in light of this anonymised feedback. The process would repeat until the group converged, or until it became clear where genuine disagreement remained1.
They named it after the Oracle at Delphi, the ancient Greek priestess at the Temple of Apollo who was believed to channel collective wisdom to answer questions about the future. The parallel was deliberate: both the Oracle and the method attempted to synthesise knowledge that no single individual possessed into a judgement that could guide consequential decisions.
The results of that first study were classified. They remained unknown to the broader research community for a decade, until RAND declassified the original report The Use of Experts for the Estimation of Bombing Requirements and Dalkey and Helmer published their methodology in Management Science in 19631. By then, the method had already been adapted far beyond military forecasting. Within subsequent decades, it would become widely used in healthcare, education, and health-services research.
The problem the Delphi method was designed to solve in 1951 is the same problem that every clinical guideline panel faces today: how do you get an accurate consensus from experts when the evidence is incomplete, when the experts disagree, and when the social dynamics of a group discussion risk producing a recommendation that reflects the loudest voice rather than the best available judgement? The architecture of the method: anonymity, iteration, controlled feedback exists to protect against exactly these distortions.
And yet, Delphi is only one of several structured consensus approaches available to guideline developers. Each has distinct procedures, strengths, and trade-offs. The choice of method shapes the quality of the recommendations, the efficiency of the process, and the credibility of the final document.

In its classical form, the Delphi method proceeds through multiple rounds, typically two to four, of anonymous questionnaires. After each round, a facilitator provides an anonymised summary of the group’s responses, including the distribution of ratings and the reasoning behind outlier positions. Panellists revise their answers in light of this feedback. The process continues until a predefined consensus threshold is met, often defined a priori as 70% or 75% agreement, or until responses stabilise across rounds2.
Classical Delphi often involves 10 to 30 experts, although no single optimal size is mandated, and does not require a face-to-face meeting, making it well suited to geographically dispersed panels. Its defining strength is anonymity: because panellists do not know who holds which position, the method mitigates deference to seniority, reluctance to challenge a dominant voice, and the anchoring effect of early speakers2.
The trade-off is the absence of real-time deliberation. Panellists cannot ask clarifying questions, challenge reasoning, or build on one another’s ideas in the moment. This can lead to convergence without depth. Additionally, the iterative nature introduces logistical challenges, including panellist attrition, survey fatigue, and prolonged timelines associated with repeated rounds of feedback and analysis3,4.
The modified Delphi addresses the deliberation limitation of classical Delphi by combining anonymous voting with a face-to-face or virtual meeting and is widely used in healthcare and medical education research2,5.
A typical modified Delphi process involves an initial anonymous survey round, followed by a structured meeting where areas of disagreement are discussed openly, and concluding with a final anonymous voting round. The discussion phase allows the nuanced exchange that classical Delphi lacks, while the anonymous final vote preserves the protection against social influence bias that makes the Delphi approach valuable in the first place.
Panel size, consensus definitions, and study duration vary considerably across modified Delphi studies. However, many healthcare applications use panels of approximately 10 to 20 participants and define consensus prospectively at around 70% to 80% agreement2,5.
For many clinical guideline and consensus statement projects, particularly those involving relatively small panels addressing a defined set of clinical questions, the modified Delphi has become the preferred structured consensus approach, and for good reason. It balances rigour with feasibility. It is the method Helmer and Dalkey might have designed if they had been building consensus on treatment protocols rather than bombing targets.
The nominal group technique (NGT) takes a fundamentally different structural approach. Rather than relying on multiple iterative rounds of anonymous questionnaires, NGT brings panellists together for a single structured session with tightly controlled discussion and voting procedures2,5.
The session proceeds through four phases:
The critical design feature is the separation of idea generation from discussion and from voting. By requiring silent independent generation before any sharing occurs, the method ensures that every panellist contributes their own thinking before being influenced by others. The round-robin format gives equal airtime to every participant. Independent final voting prevents the discussion from overriding individual judgement2.
NGT is generally best suited to smaller groups, often in the range of 5 to 12 participants per session, and is particularly effective for priority-setting, identifying key research questions, and situations where consensus is needed quickly. It is typically conducted within a single structured session rather than across multiple rounds. The limitation is that it is less iterative than Delphi: there is no opportunity for panellists to reconsider their positions across multiple rounds in light of anonymised group feedback.
The RAND Corporation contributed not only the Delphi method but also, decades later, the RAND/UCLA Appropriateness Method (RAM), developed in the 1980s specifically to assess the appropriateness of medical and surgical procedures for defined clinical scenarios6.
The process begins with a structured review of the available evidence, which is provided to the panel in advance. Panellists independently rate detailed clinical scenarios on a 1-to-9 scale, with 1 representing extremely inappropriate care and 9 representing extremely appropriate care. A face-to-face meeting follows, during which areas of disagreement are discussed. Panellists then independently re-rate the scenarios after the discussion session. Appropriateness is determined by the median panel rating and the degree of agreement: a median of 7 to 9 without disagreement is classified as “appropriate,” 1 to 3 without disagreement as “inappropriate,” and all other results as “uncertain”6.
RAM is a well-established and extensively applied consensus methodology and produces highly specific outputs, but it is labour-intensive. The development of clinical scenarios requires significant upfront work, and the method is best suited to procedural and intervention-specific questions: “when is it appropriate to perform coronary revascularisation in a patient with these characteristics?” rather than the broader therapeutic questions that most clinical guidelines address. It has informed appropriateness criteria and consensus frameworks used by organizations such as ACC/AHA and ACR.
The consensus development conference model was established by the NIH in 1977 and operated for over three decades, producing more than 160 consensus and technology assessment statements before the programme concluded in 2013.
The format is distinctive: a 1.5- to 2.5-day public conference in which invited experts present evidence to an independent jury-style panel of 10 to 14 members. The panel, separate from the presenting experts, deliberates in closed session and produces a written consensus statement addressing predefined questions. The statement is read publicly and subsequently published2,7.
The model’s strength lies in its transparency and the structural separation between those presenting the evidence and those interpreting it. Its weakness is logistical: it is expensive, requires substantial planning, and allows limited iterative refinement. While the NIH programme itself is no longer active, the model has influenced consensus development processes worldwide.
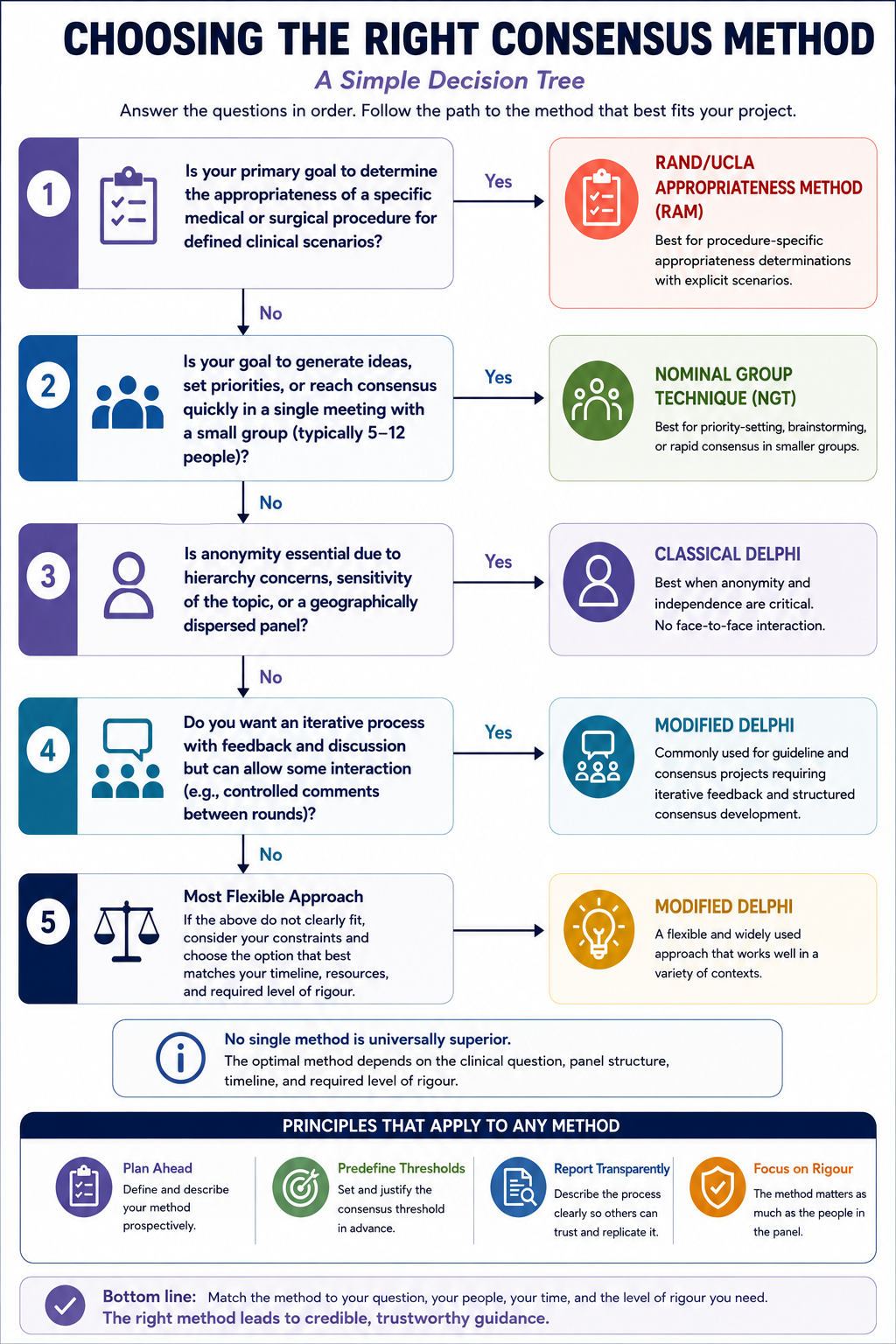
Method selection should be driven by four practical considerations:
For many guideline and consensus statement projects involving relatively small expert panels, a modified Delphi offers a practical balance between methodological rigour and feasibility. When panel hierarchy is a significant concern or the panel is geographically dispersed, classical Delphi provides stronger protection against social influence at the cost of real-time deliberation. For priority-setting exercises or situations requiring rapid consensus within smaller groups, NGT can be particularly effective. For procedure-specific appropriateness determinations, the RAND/UCLA Appropriateness Method provides a highly structured and extensively studied framework.
Regardless of which method is chosen, three elements are non-negotiable for credibility: the method must be selected and described prospectively, the consensus threshold must be predefined rather than determined after results are known, and the process must be reported transparently in the methods section of the published document2,4.
Helmer and Dalkey understood in 1951 what many guideline panels still struggle with today: the value of an expert’s opinion depends not just on their expertise but on the conditions under which that opinion is elicited. Anonymity protects honesty. Iteration promotes reflection. Controlled feedback allows convergence without coercion. The method matters as much as the people in the panel and getting it right at the outset determines whether the final recommendations reflect genuine collective wisdom or simply the views of whoever spoke loudest.
References