
May 20, 2026

This is the first in a five-part series on the science and methodology behind clinical practice guidelines and consensus statements. The series “From Hippocrates to Delphi” is named for the arc that connects the earliest attempts to codify medical practice to the structured consensus methods we use today. Hippocrates gave us the idea that clinical knowledge should be written down and shared. The Delphi method, named for the ancient Greek oracle, gave us a way to systematically extract and refine collective expert judgement. The 2,500 years between them is the story of how medicine learned to turn opinion into evidence and evidence into recommendations. This series is for anyone involved in developing, commissioning, or evaluating clinical guidelines whether you are a physician leading a panel, a society planning a guideline programme, or a medical affairs professional trying to understand what separates a credible document from one that merely looks the part.
Sometime around the fifth century BCE, on the Greek island of Kos, a physician did something that would quietly reshape the practice of medicine for the next two and a half millennia. What did he do that was so revolutionary? He wrote it down.
The Hippocratic Corpus, a collection of roughly 60 medical treatises compiled between the sixth and third centuries BCE, was not the work of a single author, and much of what it prescribed was wrong by any modern standard. But its significance was not in the accuracy of its treatments. It was in the premise that clinical knowledge could be systematised, codified, and transmitted in writing so that physicians beyond the author’s immediate circle could follow a shared standard of practice. The Corpus covered diagnosis, prognosis, surgery, obstetrics, nutrition, and therapeutics. It told physicians what to look for, what to do, and what to expect. It was, in the most fundamental sense, an early ancestor of clinical guidance 1,2.
For the next two thousand years, that basic model of authoritative text prescribing how to practice remained essentially unchanged. Galen built on Hippocrates in the second century. Medieval physicians deferred to both. Medical knowledge was transmitted through canonical texts, and the authority of the text rested on the reputation of the author rather than on any systematic evaluation of evidence.
The modern era of clinical guidelines began surprisingly recently, in 1931. That year, the American College of Surgeons published what are widely regarded as the first formal clinical practice guidelines: one for organising cancer services in hospitals and another for fracture care. In 1938, practice guidelines for children’s immunisation followed. The period after World War II, fueled by an unprecedented expansion of government-funded medical research, saw an explosion of guidelines across oncology, coronary disease, and other rapidly evolving fields 3,4.
But it was not until 1992 that the Institute of Medicine provided the definition that would anchor the modern guideline movement: clinical practice guidelines are “systematically developed statements to assist practitioner and patient decisions about appropriate health care for specific clinical circumstances”5. That definition with its emphasis on systematic development and its orientation toward both practitioners and patients drew a line between guidelines and everything that had come before. For the first time, the authority of a clinical recommendation was tied not to the eminence of its author but to the rigour of its methodology.
Everything that followed the GRADE framework for evidence appraisal6, the AGREE instrument for guideline quality assessment7, the IOM’s 2011 standards for trustworthy guidelines was built on the foundation of that 1992 definition8. And the Delphi method, first developed by the RAND Corporation in the 1950s for defense forecasting, and subsequently adapted for healthcare consensus (more on this in part 3 of this series), provided the structured approach to expert agreement that complements systematic evidence review when evidence alone cannot drive recommendations9,10.
The fundamental impulse has not changed since Kos: let us agree on the best way to treat this and write it down so others can follow. What has dramatically changed is how we determine whose opinion counts, how we weigh it, and how we ensure that what gets written down is trustworthy. This series is a guide to those distinctions: what they mean, why they matter, and how to apply them in practice.

The terms “guideline,” “consensus statement,” “position statement,” and “expert opinion” are frequently used interchangeably, but they really should not be. Each represents a different level of methodological rigour and carries different weight in clinical and regulatory decision-making.
The distinction matters because clinicians, policymakers, and payers assign different weight to different document types. A clinical practice guideline developed through systematic review and formal evidence appraisal carries more authority in formulary decisions, insurance coverage determinations, and quality-of-care assessments than an expert opinion piece and it should, because the methodology behind it is more rigorous. Mislabelling a consensus statement as a guideline or publishing an expert opinion with the structural trappings of a formally graded document, creates confusion at best and erodes trust at worst.
The Institute of Medicine updated and sharpened its definition in 2011, describing a clinical practice guideline (CPG) as a document containing “recommendations intended to optimize patient care that are informed by a systematic review of evidence and an assessment of the benefits and harms of alternative care options”8. The key words are systematic review and assessment of benefits and harms a document that lacks either is, by the IOM’s definition, not a CPG regardless of what it calls itself.
The hallmarks of a trustworthy CPG include transparent methodology, a multidisciplinary development panel screened for conflicts of interest, a systematic evidence review, formal grading of evidence quality and recommendation strength, external peer review, and a stated plan for updating7,8. Frameworks such as GRADE and appraisal tools such as AGREE II exist specifically to standardise and evaluate these elements6,7.
Examples of organisations that produce CPGs meeting these standards include the World Health Organization, the National Institute for Health and Care Excellence (NICE), and specialty societies such as the American Gastroenterological Association and the Endocrine Society.

A consensus statement is developed when a panel of experts is convened to address a clinical question through structured deliberation. The NIH Consensus Development Program, launched in 1977 and active for several decades, became an influential model for formal consensus development conferences.
Unlike a CPG, a consensus statement does not require a formal systematic review as its evidentiary foundation, though it may incorporate one. Its strength lies in structured consensus methodology typically Delphi, modified Delphi, nominal group technique, or a consensus development conference format which introduces procedural rigour to what would otherwise be unstructured expert discussion9,11.
Consensus statements are most appropriate when the evidence base is too limited, conflicting, or immature for a systematic review to meaningfully drive recommendations, and expert judgement must fill the gap. They are also well suited to emerging clinical questions, disease classification, and areas where practice varies widely and standardisation is needed.
The critical requirement is that the consensus methodology is described transparently. A document that states only that recommendations were developed by “expert consensus” without specifying the method used, the number of rounds, the definition of consensus, or how disagreements were handled limits the reader’s ability to appraise the rigour and reproducibility of the process9.
A position statement represents the official stance of a professional society or organisation on a clinical, scientific, or policy issue. It may draw on published evidence but is typically intended to communicate an organization’s official clinical or policy position, rather than to establish recommendations through a formal evidence appraisal process12. Position statements from organisations such as the European Menopause and Andropause Society, the American Diabetes Association, and the American Heart Association serve to communicate a society’s collective view and often inform clinical practice, particularly in areas where formal CPGs do not yet exist.
The key distinction is intent: a CPG aims to tell clinicians what the evidence supports; a position statement communicates what a society believes. The two frequently overlap, but they diverge when a society’s position outpaces the available evidence.
Many organisations publish practical guidance for clinicians under titles such as “clinical guide,” “practice guidance,” or “recommendations.” These documents often rely on targeted or narrative evidence synthesis combined with expert panel discussion, rather than a full systematic review13. They are less methodologically rigorous than formal CPGs but more structured than position statements.
This category is common in practice because it fills a pragmatic need: not every clinical question justifies the time, cost, and expertise required for a full systematic review and GRADE assessment. Clinical guidance documents are appropriate when the developing body aims to provide evidence-informed recommendations efficiently, acknowledging the limitations of a narrative synthesis approach.
A best practice statement provides recommendations in areas where high-certainty comparative evidence may be unavailable or impractical to generate, and therefore relies on a combination of available evidence, expert consensus, and accepted standards of care13. These are common in nursing, allied health, and perioperative care, where many clinical questions involve procedural or system-level decisions that do not lend themselves to traditional RCT design.
Appropriate use criteria determine the appropriateness of a specific procedure, test, or therapy for defined clinical scenarios. They are typically developed using the RAND/UCLA Appropriateness Method, in which panelists independently rate clinical scenarios on a numerical scale, discuss areas of disagreement, and re-rate14. The methodology is highly structured and well validated, but it is best suited to procedural and intervention-specific questions rather than broad therapeutic guidance.
An expert opinion represents the view of one or more recognised authorities without a formal methodology for evidence synthesis or consensus building. It occupies the lowest rung of the evidence hierarchy but remains valuable when other evidence does not exist, particularly for emerging clinical questions, rare diseases, and situations where rapid guidance is needed12.
See content credentials
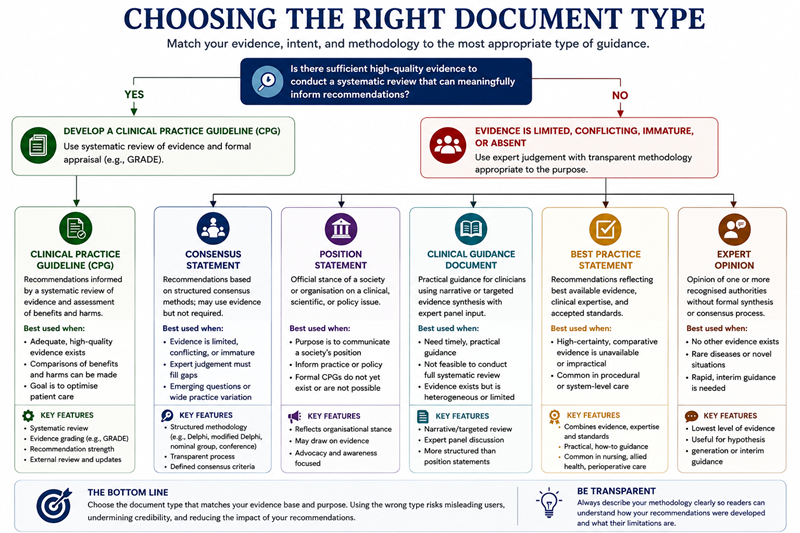
Choosing the wrong document type for the available evidence creates a mismatch that reviewers, journal editors, and end users will identify. A consensus statement that presents itself as a CPG will be judged against CPG standards and found wanting. A CPG built on a thin evidence base, where a consensus statement would have been more appropriate, risks producing recommendations that overstate the certainty of the underlying data.
The decision should be driven by a straightforward question: does the evidence base support a systematic review that can meaningfully inform recommendations? If yes, develop a CPG. If not, because the evidence is limited, conflicting, or absent, a consensus statement with transparent methodology is the more honest and often more useful product.
Getting this right at the outset saves time, protects credibility, and produces a document that serves its intended audience. Hippocrates did not have the luxury of choosing between a Delphi process and a GRADE assessment. We do, and getting the choice right is where credible guideline development begins.
Next in the series, we untangle the alphabet soup of evidence appraisal: what GRADE, AGREE, and similar frameworks measure, when and where to use them, and why they matter.
References